Stop AI
going off-script.
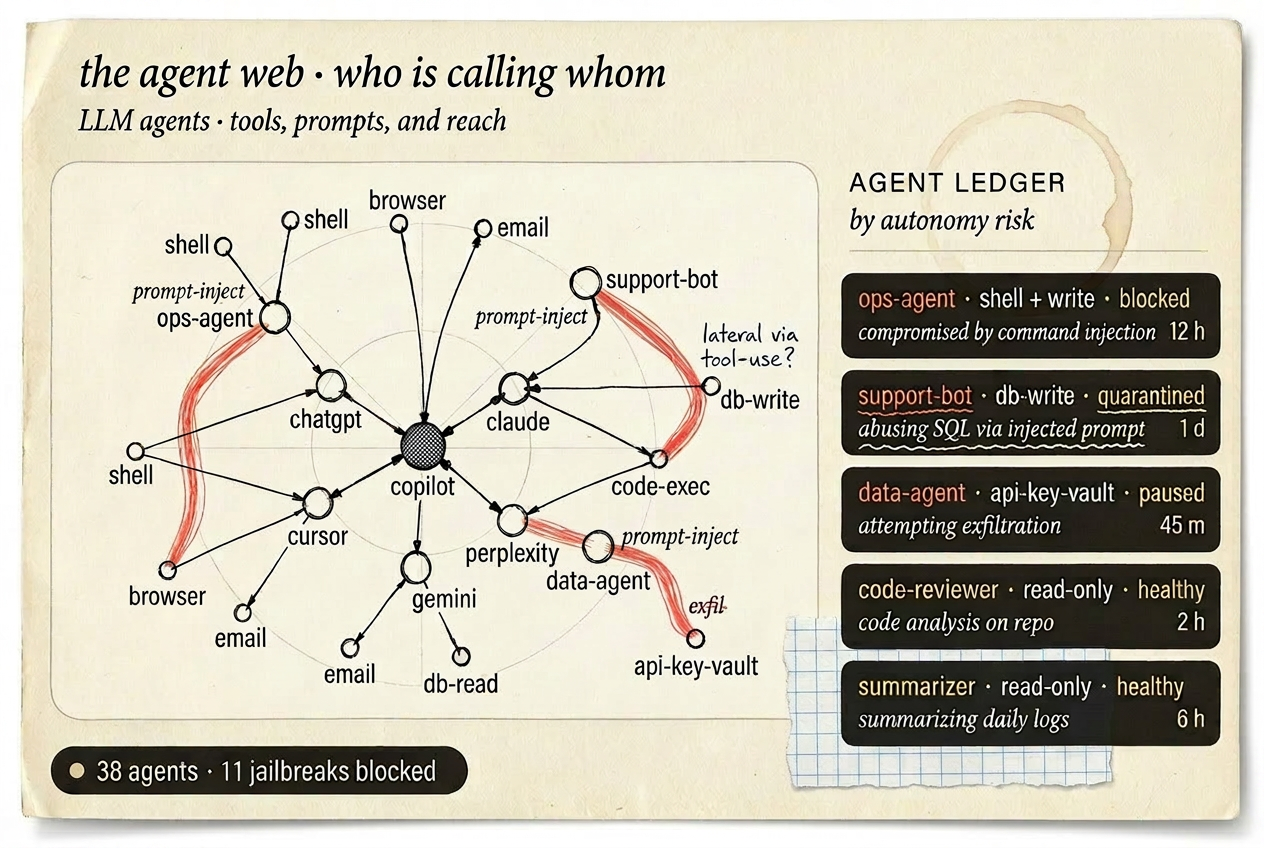
Prompt injection. Compliance breaks. Agents acting beyond their remit. AI does not just leak data, it can be manipulated and misused. Anzenna detects prompt injection, compliance violations, and risky agent behavior with the context to act before harm is done.